Real Objects Become Digital Assets.
We create high-fidelity 3D models of industrial hazard objects — traffic cones, barriers, warning signs, equipment. These aren't just meshes; they include physically accurate materials, textures, and reflectance properties so the simulator can render them under any lighting condition.

Photorealistic Environments at Scale.
3D assets are loaded into CARLA and NVIDIA Omniverse simulators. We place them in varied factory and tunnel environments with randomised lighting, camera angles, occlusions, and backgrounds. Every frame is auto-labeled by the simulator at render time.

SynYOLO — Trained on Synthetic. Deployed on Real.
SynYOLO is our detection architecture built on YOLOX, trained exclusively on synthetic data generated in photorealistic simulation. Unlike standard YOLOX models that require thousands of manually labeled real images, SynYOLO learns entirely from rendered scenes — and transfers directly to real factory cameras. No annotation teams. No labeling bias. Ground truth comes free from the simulator.
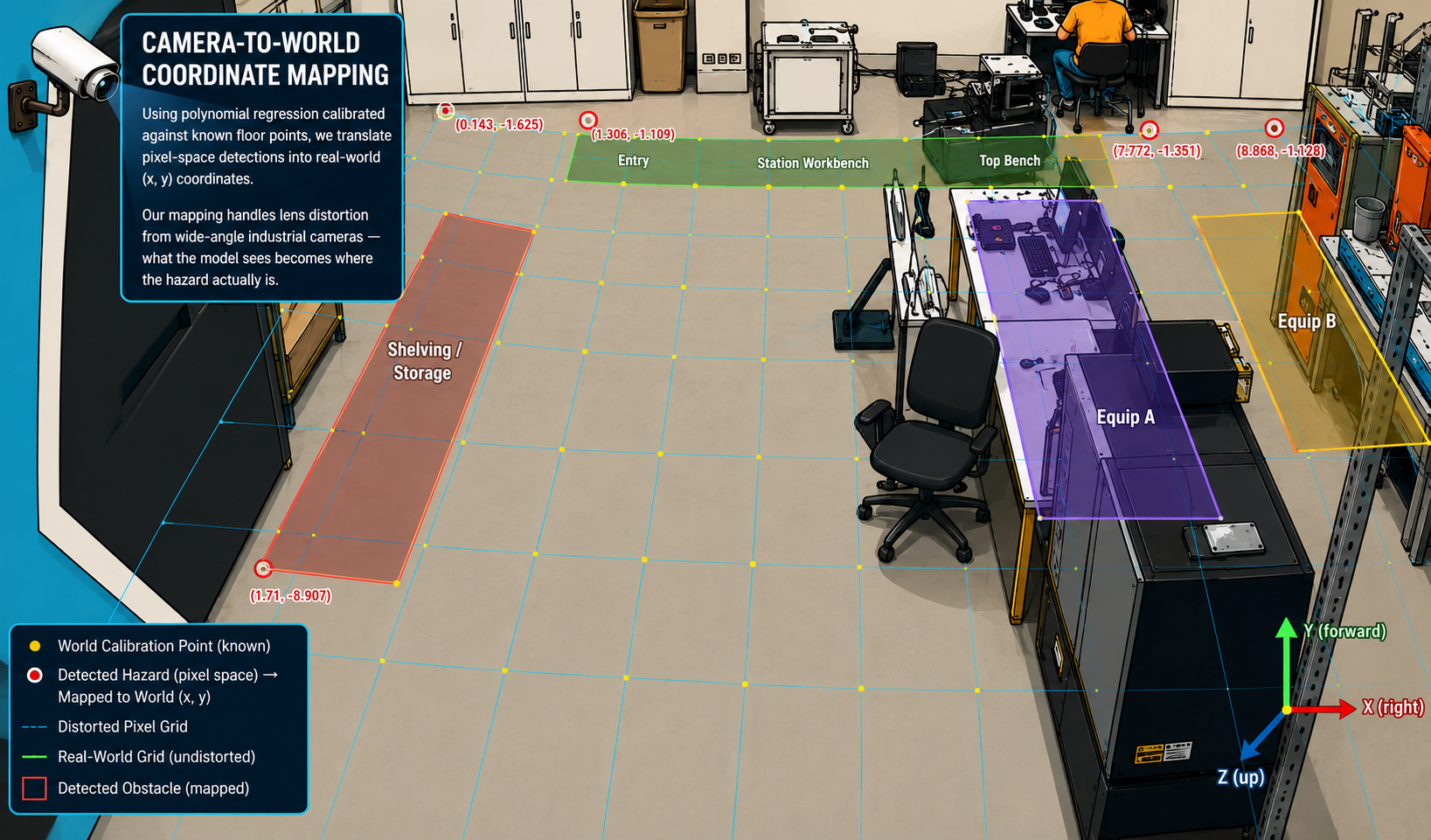
Camera-to-World Coordinate Mapping.
Using polynomial regression calibrated against known floor points, we translate pixel-space detections into real-world (x, y) coordinates. Our mapping handles lens distortion from wide-angle industrial cameras — what the model sees becomes where the hazard actually is.
Real-Time Detection on Factory Cameras.
The trained model runs inference on live camera feeds. Detected objects are localised in world coordinates and fused with existing 5G / UWB positioning systems for complete situational awareness — a single, coherent picture of where every hazard is, in real time.
